Na začátku května (2017) jsme dostali možnost na několik týdnů využít k testování server nové generace od Wedos s tím, že jej smíme zatížit, jak uznáme za vhodné. Čím více, tím lépe. Zátěžový test knihovního systému Koha jaký v Česku ještě nebyl? To by bylo něco! A protože nás už delší dobu zajímal skutečný výkon při zpracování velkého objemu dat, neváhali jsme. Výsledky nyní přinášíme v přehledné formě. Veříme, že mohou být zajímavé pro každou knihovnu, která systém Koha používá nebo uvažuje o jeho zavedení. Pohodlně se usaďte, velký test Kohy právě začíná!
Jak jsme testovali
Při testování jsme se chtěli zaměřit na několik oblastí. Zajímal nás
- (1) výkon systému během importování záznamů
- (2) rychlost indexování celé databáze
- (3) zatížení procesoru během indexování
- (4) nároky na diskovou kapacitu, tedy kolik prostoru systém skutečně spotřebuje
- (5) rychlost načítání hlavní stránky rozhraní systému
- (6) rychlost načtení detailu záznamu
- (7) rychlost načtení detailu čtenáře
- (8) rychlost provedení výpůjčky a její vracení
Rychlost importu (1) jsme měřili nadměrným požadavkem, kdy jsme do systému nahráli téměř milion biblio záznamů. Ty byly uloženy v souboru o velikost přesahující 4 000 MB (4 GB). Následně jsme nechali všechny tituly indexovat a měřili jsme rychlost indexování (2) a zatížení procesoru (3). Po dokončení této operace jsme zjistili, jak velkou část disku systém obsadil svými daty (4). Následovala výše zmíněná čtyři rychlostní měření, říkejme jim třeba časovky (5, 6, 7, 8). Pro ně jsme spustili již připravený test, který využívají také vývojáři Kohy při optimalizaci výkonu. Při každém z časovkových testů proběhlo 200 identických úkonů pro předem definovaný počet uživatelů. Cílem bylo zjistit, jak se systém chová v případě, že jej využívá jen málo nebo naopak hodně uživatelů. Nešlo tedy o to, jak přesně dlouho jednotlivé úkony trvají, ale jak dobře dokáže systém škálovat výkon s rostoucím počtem uživatelů. Výsledky mohou být překvapující.
Konfigurace testovacího serveru
| Počet procesorů | 1 CPU |
|---|---|
| Počet vláken procesoru | 4 VCPU |
| Kapacita operační paměti | 15 GB RAM |
| Velikost systémového disku | 30 GB SSD |
| Velikost disku pro data | 48 GB SSD |
Nejednalo se tedy o žádné ořezávátko, ale solidně vybavený server s kapacitou odpovídající plánovanému zatížení.
(1) výkon systému během importování záznamů
Pro import jsme připravili přibližně 4GB soubor (ve standardním formátu MARCXML) a spustili dávkový import celého velkého balíku dat. Import trval 32 415 sekund, což odpovídá téměř přesně 9 hodinám. Během této doby systém načetl 957 082 titulů obsahujících 1 501 639 knižních jednotek. Za sekundu tak bylo v průměru načteno téměř 30 titulů se 46 jednotkami. Kompletní bibliografie středně velké městské knihovny běžně čítající 50 000 svazků by tak byla načtena asi za 18 minut, což také odpovídá našim zkušenostem při zprovozňování knihoven.
(2) rychlost indexování celé databáze
Aby Koha dokázala rychle a přesně vyhledávat, musí se všechna data indexovat. Indexování je nejdůležitější součástí všech vyhledávačů jako je např. Google či Seznam, kde tento proces probíhá neustále. Koha využívá starší indexovací nástroj Zebra, který je však od verze Kohy 17.05 nahrazen moderním indexovacím strojem ElasticSearch. Verze 17.05 však vyšla až po ukončení našich testů. Reindexování kompletní databáze Zebrou trvalo 9 970 sekund, tedy přibližně 2 hodiny a 46 minut. Také tento údaj odpovídá našim zkušenostem z provozování Kohy v knihovnách. Za běžného provozu však indexování server nijak nezatěžuje, protože každý záznam je indexován okamžitě při jeho katalogizaci, tedy postupně jeden po druhém narozdíl od našeho dávkového testu. Za jedinou sekundu tak Koha zvládla indexovat 96 záznamů, což je přibližně 3x více, než stíhala uložit během importu dat.
(3) zatížení procesoru během indexování
Při indexování si Koha v prvním kroku připraví indexovací podklady a ve druhém pak probíhá vlastní reindex. Po celou dobu je procesor serveru plně vytížen. V první fázi (na grafu odpovídá času 10:15 - 12:10) je výkon velmi vyrovnaný a téměř nevybočuje z hladiny 100 %, druhá fáze (přibližně 12:10 - 13:00) je o něco labilnější, proto výkon kolísá mezi 100 - 120 % výkonu virtuálního serveru.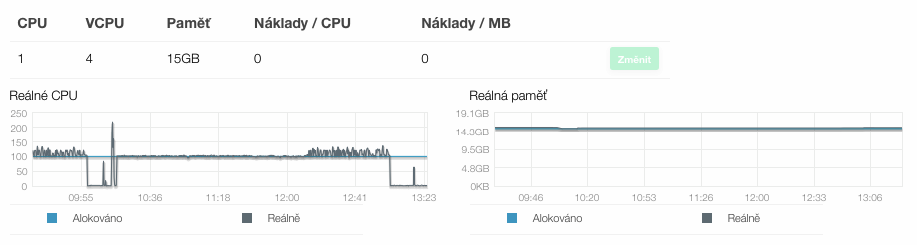
(4) nároky na diskovou kapacitu
Velikost disků jsme v prvních fázích testu neodhadli správně a tak jsme postupně navyšovali kapacity od počátečních 20 GB jediného disku až na celkových 78 GB prostoru na dvou oddělených discích. Tato kapacita již byla dostatečná včetně slušné rezervy pro případná budoucí data. Po dokončení importu dat a jejich následném reindexování bylo obsazení systémového disku 46 % a datového disku 36 %. Problém však byl v tom, že během indexování kolísalo obsazení datového disku i přes 20 GB, proto jsme nakonec při opakováných testech pro jistotu zvolili kapacitu blízkou 50 GB.
| Disk | Velikost | Obsazeno | Volno | Obsazeno % |
|---|---|---|---|---|
| Systém | 30 GB | 14 GB | 16 GB | 46 % |
| Data | 48 GB | 17 GB | 31 GB | 36 % |
(5, 6, 7, 8) rychlost načítání stránek rozhraní systému - časovky
Tyto testy fungovaly tak, že automatizovaný proces simuloval co nejrychleji za sebou 200 velmi podobných požadavků na nejčastěji využívané stránky v rozhraní systému. Jednalo se o
- rychlost zobrazení hlavní stránky,
- načtení detailu biblio záznamu,
- načtení stránky s profilem čtenáře,
- rychlost provedení výpůjčky a vrácení.
Shodná měření byla provedena pro 4, 10, 20 a 100 uživatelů. Rozdíly naměřených hodnot jsou v řádu milisekund a tedy za běžného provozu neznatelné. Je však patrné, že vyšší počet uživatelů systém nezpomaluje. Často je v tomto módu srovnatelně rychlý jako s řádově menším počtem uživatelů. V animovaném grafu jsme museli počáteční hodnotu časové (vodorovné) osy posunout do 5000 ms, abychom vůbec mohli rozdíly mezi jednotlivými testy zobrazit. Ze získaných údajů je patrné, že na zobrazení jedné stránky systém potřebuje přibližně 30-40 ms. Pokud si uvědomíme, že mrknutí oka trvá přibližně 50 ms a na zpracování obrazu potřebujeme dalších 150 ms (zdroj: Česká televize), pak je zobrazení stránek uživatelského rozhraní Kohy doslova okamžité.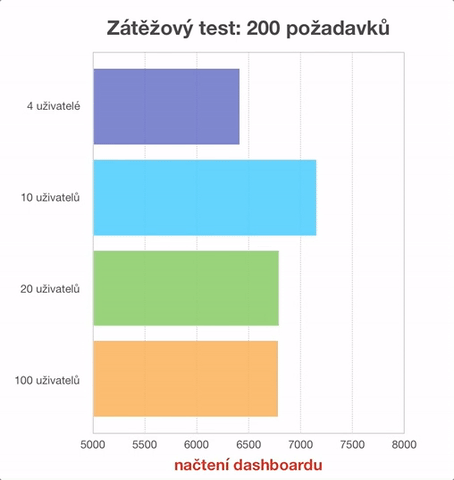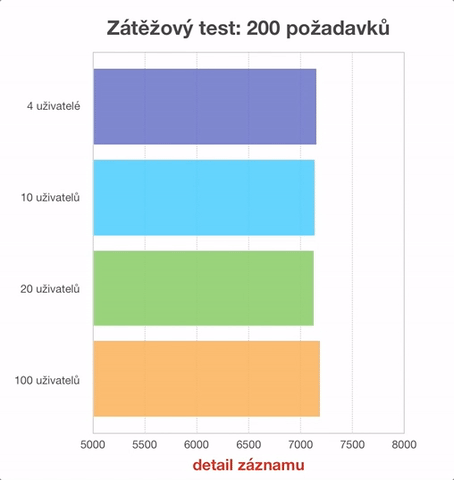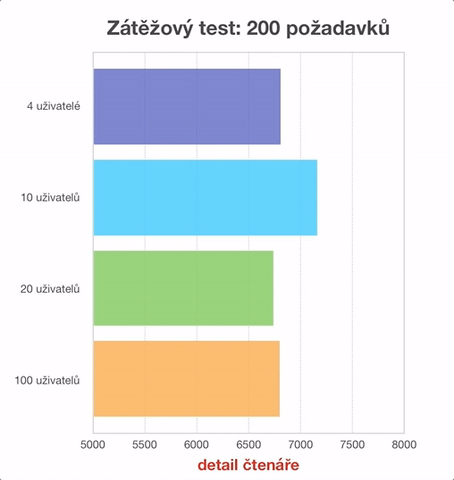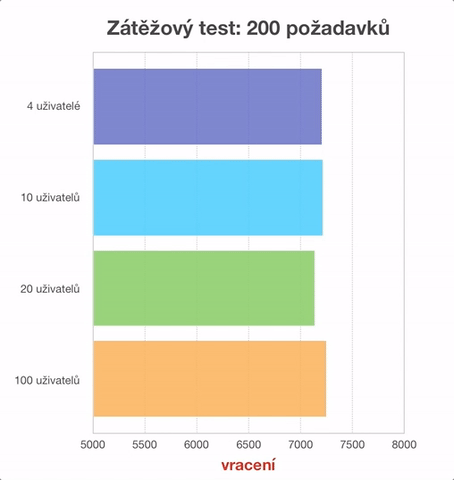
Závěr
...v laboratoři
Při instalaci na server odpovídající konfigurace (rozumně dostupné) je odezva systému více než dostačující. Desítky milisekund nutné k zobrazení jedné stránky systému jsou za běžného provozu nepozorovatelné. Při laboratorních podmínkách je webová aplikace Koha srovnatelná s běžnou desktopovou aplikací. Nespornou výhodou webu je jeho přístupnost z kteréhokoliv místa a navíc přes libovolný počítač či mobilní zařízení (telefon, tablet) připojené k internetu. A to vše bez nutnosti cokoliv instalovat.
Větší objemy dat mají celkem pochopitelně vyšší nároky na diskové kapacity. Je potřeba počítat s obsazením přibližně 5násobku velikosti datového souboru ve formátu MARCXML. Tento prostor zaberou především indexovací data. Při dnešních kapacitách a cenách disků jsou však desítky GB legitimním požadavkem.
Knihovní systém Koha je tedy dostatečně rychlý, aby dokázal obsloužit knihovnu prakticky libovolné velikosti i dostatečně úsporný, aby mohl být provozován na běžné konfiguraci současných serverů.
...ve skutečné knihovně
Subjektivní realita běžného provozu se pochopitelně v určitých ohledech více nebo méně liší od skleníkových podmínek uvedených objektivních laboratorních testů. V praxi se jen těžko podaří vrátit 200 knih za 7 sekund. Skutečná rychlost systému tak hodně závisí na konkrétní situaci, kdy musí webový prohlížeč komunikovat se serverem častěji, dotazovat se obsluhy např. na to, zda opravdu znovu půjčit již dřívě půjčený titul apod. Tato interakce s obsluhou celkový čas na odbavení jednoho čtenáře logicky prodlužuje, někdy i na několik minut. Vývojový tým Kohy však intenzivně pracuje na optimalizacích jednotlivých provozních transakcí a navazujících procesů a to nejen po technické stránce (použití lepších technologií), ale i po stránce vylepšování přívětivosti systému (UX - user expirence, tedy proces vylepšování uživatelské spokojenosti s produktem).